Base64 is a binary-to-text encoding scheme that is used to represent binary data in an ASCII string format. ASCII stands for American Standard Code for Information Interchange. ASCII encoding takes the raw binary data and translates predefined groups of bits into numbers. So-called ASCII-Tables map those numbers against characters, signs and human readable numbers. Therefore the ASCII-Encoding enables us to represent binary data in human readable form and more important, it also enables us to share /work with /distribute data without loosing the original informations stored within the binaries. The more bits are used in those before mentioned predefinded groups of bits, the larger the numbers that can be represented, and the more characters can be mapped by the ASCII-encoding scheme. The following table contains a few examples for such an encoding. (Note: ASCII does differentiate between upper- and lowercase characters. The character ‘a’ for example is represented by 97 while ‘A’ is represented by 65!)
| ASCII | Decimal Value | Binary-Value (Bits) |
|---|---|---|
| A | 65 | 0100 0001 |
| B | 66 | 0100 0010 |
| C | 67 | 0100 0011 |
| … | … | … |
| Z | 90 | 0101 1010 |
| 7 | 55 | 0011 0111 |
Base64 is one of those encoding schemes that maps numbers against different characters. To do that, it uses groups of 6 bits. As those 6 bits can represent 26 = 64 characters the encoding scheme is called Base64. As modern encoding schemes and data formats are more likely to use more bits than this ( f.e. utf-32 uses 32 bits to index a single number and the standard ASCII used 7 Bits ) the Base64 representation of data is complete gibberish in most cases as it does map only the basic characters due to limited numbers. As Base64 is mapping different characters to corresponding numbers the Encoding is not compatible to ASCII or utf-encoding
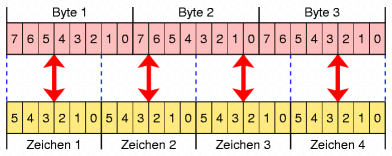
Source: Wikipedia
{kind=link}
If the number of bytes in a file cannot be devided by three, and therefore the transformation as shown above would not work, the decoding algorithm does fill the missing gaps with zero-bits until the Encoding can be done. To tell the decoder how many fill bytes have been appended to the original file, the 6-bit blocks that have been created entirely from fill bytes are encoded with =. Thus, at the end of a Base64 encoded file no, one or two ‘=’ characters can occur. This process is called padding. The complete Base64 index table is shown below:
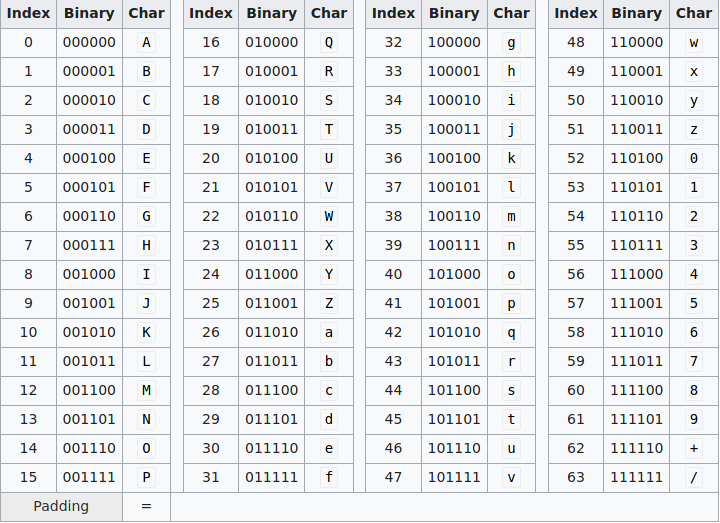
You may ask yourself: Why do we need Base64 – encoding? Why don’t we use the nowadays common (and more data-intensive!) encoding-schemes with more characters available? The answer is simple:
The Internet is quite old. And even if there are more advanced ways of implementing data transmission these days, we still rely on services, protocols and software in general that are pretty old at their core on a daily basis. Base64 is originally designed for the transmission of data that is stored in binary formats across channels, that only reliably support text content. It enables us to send images or archive-files inside of textual assets.
One example is the SMTP-Protocol. The Simple Mail Transfer Protocol was originally designed for the transport of 7-Bit-ASCII characters only. If we want to maintain the backwards compatibility for this protocol we still have to use good old Base64 Encoding.
To encode or decode text data manually to base64 or from bas64 into human readable text you can use one of the several web-applications out there. As an alternative you can convert strings directly into base64 using the shell.


Lastly i should note, that those are not the only two ways to quickly encode / decode Base64 data. Most programming languages have modules doing this fore you. f.e. python comes with the base64-module.
Hope you could follow along! 🙂
No Responses